From a recent topic in Wesnoth.org’s Game Development forum:
[...] this is also quite close to advertisement, but you don't have the traits of a spammer.
This is one of my major qualms about the current organization of the Wesnoth.org forums. The non-indicative Game Development section was indeed created for that specific purpose of serving as a venue for advertising other games and potentially recruiting contributors. The definition of spam for this section is sketchy at best, but common sense suggests that the following forms of promotion would be off-limits:
Advertising things that are not games
Blatant advertising by posting links to different topics
Misleading information/scam
If advertising in GD in general was considered spam, then the forum would be nearly or entirely empty. The question is, why do we provide this marketing channel in the first place? It seems to me like the primary goal is promoting open-source game development, but the forum description implies that this is not a strict requirement for posting there. I am not terribly comfortable with the idea that it should be our mission to do this seeing as how there are larger and better organized communities for this kind of thing, but I can see how some people might prefer to have means to preach to the world at large without having to maintain a blog or register accounts on other boards.
Quite lazy, if you ask me.
But all this is fine by me as long as I’m not forced to read every single topic that crops up in there.
Just as irker’s adoption rate is increasing, I have just completed work on a very simple application for Subversion repositories — two applications, in fact.
irker-svnpoller is a very simple script that polls a single commit log (not data) from a Subversion repository and delivers notifications to any number of channels using an irkerd running on the same host. It mimics the CIA bots’ formatting, much like nenolod’s irker CIA proxy, from which I borrowed a small amount of code.
irker-svnpoller → irkerd
But exactly how is this supposed to be useful to anyone, you may be wondering right now? Well, irker-svnpoller is not really intended to be used stand-alone. A timed poller script that tracks the last notified revision could come in handy, but people could get impatient waiting for their commits to appear in their IRC channels minutes later. I am well familiarized with the defects, quirks, and virtues of my primary audience—the Battle for Wesnoth and Wesnoth-UMC-Dev projects—and this approach would simply not scale well over time.
Enter the first companion script, svnmail-filter. It reads email message headers from stdin to determine a commit’s revision number and the pertinent repository to probe using irker-svnpoller. Configuration is mostly done through a ruleset file using the JSON format.
Of course, svnmail-filter is not that useful on its own either. The idea is that procmail or some other MDA should pipe incoming email headers through svnmail-filter — and preferably, only those from legitimate sources, such as subscribed commit mailing lists. This is actually simpler than it sounds, and it is more or less inspired by CIA.vc’s perpetually broken mail-based SVN poller.
MDA → svnmail-filter → irker-svnpoller → irkerd
Since no service in the pipeline other than irkerd runs persistently in the background, this should be significantly more fault-resilient than CIA.vc’s approach, which apparently required a poller service to listen and act upon local requests. The downside is that the host running irker-svnpoller may need to create many short-lived SVN repository connections for individual commits in a chain. In Wesnoth’s case, SVN commit chains are rare enough, but their size often goes around a dozen individual commits or so. Regardless, this shouldn’t be terribly concerning for a production server with a decent low-latency uplink, and the overhead on the repository provider should be rather small compared to pushing massive commit diffs across the network.
Right now, the Wesnoth and Wesnoth-UMC-Dev projects are using this service as a stopgap measure until their respective providers—Gna.org and SourceForge.net—allow installing a hook that can either talk directly to an irkerd server, or to an instance of the aforementioned CIA proxy using the CIA XML-RPC method.
I am not all that keen on other people using a piece of software I developed and tested within less than three days without any prior experience working with Python. There are also various problems inherent to any application depending upon Subversion and its incompetent network transport layer.
Nonetheless, I published a Git repository on GitHub including a small amount of documentation to get started:
I am open to possible improvements coming from people intending to use this on production servers. In particular, if someone out there works with a commit mailing list where revision numbers can’t be found in mail subjects it would be necessary to adapt svnmail-filter a little to handle that case. Perhaps it might even be possible to skip the irker-svnpoller step for mailing lists where the notification message structure is constant and well documented.
Following CIA.vc’s untimely demise, ESR and a small ad hoc group of coders and testers including nenolod (from Atheme) and our very own AI0867 (who has led Wesnoth-UMC-Dev in my absence) finally completed the work required to get irker 1.0 out. irker itself has been a work in progress for a while since the last CIA outage in August.
It’s advertised as a CIA.vc replacement, but in reality it is something far less ambitious in scope: a write-only IRC bot that serves its own message bus. From its own README:
irkerd is a specialized IRC client that runs as a daemon, allowing
other programs to ship IRC notifications by sending JSON objects to a
listening socket.
It is meant to be used by hook scripts in version-control
repositories, allowing them to send commit notifications to project
IRC channels. A hook script, irkerhook.py, supporting git and
Subversion is included in the dustribution (sic); see the install.txt file
for installation instructions.
The author’s intention is for existing code forges to adopt this service, and perhaps optionally run it on their own facilities alongside their VCSes, allowing repository admins to opt in for using hooks that deliver notifications to those internal irker instances. irker’s pipeline is extremely flexible and can be summed up as follows:
Repository hook → irker instance → IRC server
CIA.vc’s pipeline is not entirely clear to me and I did not have the opportunity to inspect it from inside, unlike ESR. However, there’s enough evidence suggesting that it was more or less like the following:
Repository hook → CIA.vc XML-RPC or mail provider → CIA.vc database manager → IRC front-end → IRC server
Note that there was also a web front-end, which was integral to CIA’s mission as it was the only way to define projects and bots. A commit notification occurred for a given project; say, Wesnoth-UMC-Dev. The IRC portion of the pipeline made sure that all relevant bots (each one associated to a single channel from the model standpoint) would report the same commit. A less relevant Web front-end in the pipeline took care of adding the commit to the project page (including statistics and an XML feed).
The IRC portion was flexible enough to accommodate the simplest use case (notifying a single project’s commits in a single channel), and more elaborate yet still reasonable use cases (notifying commits from multiple projects in a single channel) without much hassle, all done by tweaking the bots’ configuration in the web-based configuration front-end. Even more advanced use cases were possible by choosing the Advanced Filtering option in the same front-end. This allowed me to have a bot in ##shadowm on freenode report commits as follows:
Commits from wesnoth-umc-dev (already reported in #wesnoth-umc-dev) with paths matching */After_the_Storm/* and */Invasion_from_the_Unknown/*, regardless of author
Commits from my own CIA-registered projects (morningstar, weldyn, dorset, etc.) regardless of author
Commits from any other CIA-registered project (such as Wesnoth or Frogatto) with an author matching my real name or any of my preferred screen names (fun fact: never got any false positives since I set it up a couple of years ago)
I should emphasize that this required no changes to hooks in each repository. Hooks delivered just a minimal set of information, including the commit hash or number, the commit message, affected path, affected branch (when applicable), affected module (when applicable), the author name, and the project name. Everything else was done on CIA’s side, including deciding which channels should get notified of individual commits.
irker does not do this.
irker’s perceived elegance stems from its very basic and versatile design. Essentially, it serves as a mechanism for a repository hook to interact with IRC without having to establish a short-lived connection to a server for every individual commit or commit batch — an approach that GitHub currently allows via a separate, seldom used IRC service hook. irker is not novel in design by any means, and the hype around it is only justified by the fact that nobody bothered to create and advertise any other service that could properly replace CIA.vc before and be inherently extensible maintainable over time.<
irker’s extensibility and maintainability stems from the fact that a good portion of the work is done by the repository hooks, and irker is near completely stateless — the obvious opposite of CIA.vc’s architecture.
Unfortunately, this renders advanced use cases such as the above ##shadowm CIA ruleset completely incompatible with the irker pipeline.
[...] the original designer fell in love with the idea of data-mining and filtering the notification stream. It is quite visible on the CIA site how much of the code is concerned with automatically massaging the commit stream into pretty reports. I’m told there is a complicated and clever feature involving XML rewrite rules that allows one to filter commit reports from any number of projects by the file subtrees they touch, then aggregate the result into a synthetic notification channel distinct from any of the ones those projects declared themselves.
(He somehow got this part slightly wrong. Incidentally, it was me who brought it up in #cia around August 25th in the first place. The projects’ own notification channels were as synthetic as any others from CIA.vc’s point of view. That is to say, not at all. Additionally, they weren’t XML rewrite rules, but rather commit matching rules.)
His opinion is, naturally...
Bletch! Bloat, feature creep, and overkill!
Yes, I admit that it is overkill, but it was a nice thing from our point of view as users of the system. There’s a line between using a service, and administrating it.
On the plus side, seeing as how irker aims to become an actual standard for IRC feeds of any sort (not just for VCSes), it is good that it only implements the most basic functionality by itself. This should later allow us to come up with ingenious applications such as nenolod’s CIA proxy for irker (delivers CIA.vc XML-RPC requests in a format suitable for irker). Some people have even proposing building new services using irker’s protocol, adding an authentication layer on top and integrating it to IRC networks as a hosted service!
But replicating the end-user functionality a few people like me enjoyed will invariably take some additional effort. ESR suggests:
Filtering? Aggregation? As previously noted, they don’t need to be in the transmission path. One or more IRC bots could be watching #commits, generating reports visible on the web, and aggregating synthetic feeds. The only agreement needed to make this happen is minimal regularity in the commit message formats that the hooks ship to IRC, which is really no more onerous than the current requirement to gin up an XML-RPC blob in a documented format.
Of course, if the #commits channel on freenode ever regains its former glory, this would require a bot to listen to and filter possibly thousands of messages per minute, all coming from multiple clients. I don’t think I am fit to become the pioneer who’ll conquer this new land.
Furthermore, since the task of formatting messages for individual commits is exclusive to individual hooks, we may end up with a highly fragmented and inconsistent ecosystem. For example, as things stand right now, no-one is required to include #commits on freenode as a destination for commit notifications, and I imagine very few people will bother to do so in the future.
All in all, it was our own incompetence that allowed CIA.vc to die prematurely despite the multiple calls for replacing it, and the obviously deplorable service conditions. We can’t really complain now.
I normally don’t comment or report on other sites’ statuses in here since this is my personal blog, but this situation actually impacts Wesnoth, Wesnoth-UMC-Dev, and me directly; especially me, considering I went to ridiculous lengths the other day to solve a related issue on GitHub.
The point is literally the title of this post: CIA.vc is dead.
You know, CIA.vc; that amazing service which provided real-time VCS commit notifications on various IRC networks and that everyone took for granted. This is by no means the first time it bites the dust, but in this opportunity it’s suspected that nobody really bothered to make backups.
nenolod (who was merely hosting the instance running CIA.vc) explained the situation in freenode’s #cia channel about an hour ago.
Assuming the other people who had admin access don’t have their own recent backups, CIA.vc’s future looks particularly bleak right now. Here’s hoping that a dedicated team of competent coders with access to a suitable server for hosting will quickly build a better replacement within the next few days. (Ha, ha, ha. Right.)
Ever since I started using GitHub I have been greatly bothered by the questionable design decision of sending only the first line of a commit message to CIA.vc — the service that allows us to get instant commit notifications on IRC channels. For people using Git like it was intended to be used, this means you will only see the subject line for each commit in your CIA notifications and the web feed.
That’s not my only reservation about GitHub’s custom CIA hook’s design, in fact. It also limits the amount of notifications sent per push to five; more commits than that get notified as a single commit along with a “(+n more commits)” notice in the message. While everyone knows that CIA is broken by design and all, it just doesn’t feel right to me that GitHub should be in charge of manipulating notifications to avoid flooding and all. Whatever, I say.
Regardless of CIA’s perpetual state of brokenness, there is something that it currently does right. CIA bots won’t flood a channel with more than a few message lines per commit. One could then assume that this renders GitHub’s single-line commit notifications entirely pointless, but there might be people who really want their CIA bot to behave like a continuous git log --format=oneline run without figuring out a complicated CIA formatting ruleset specification.
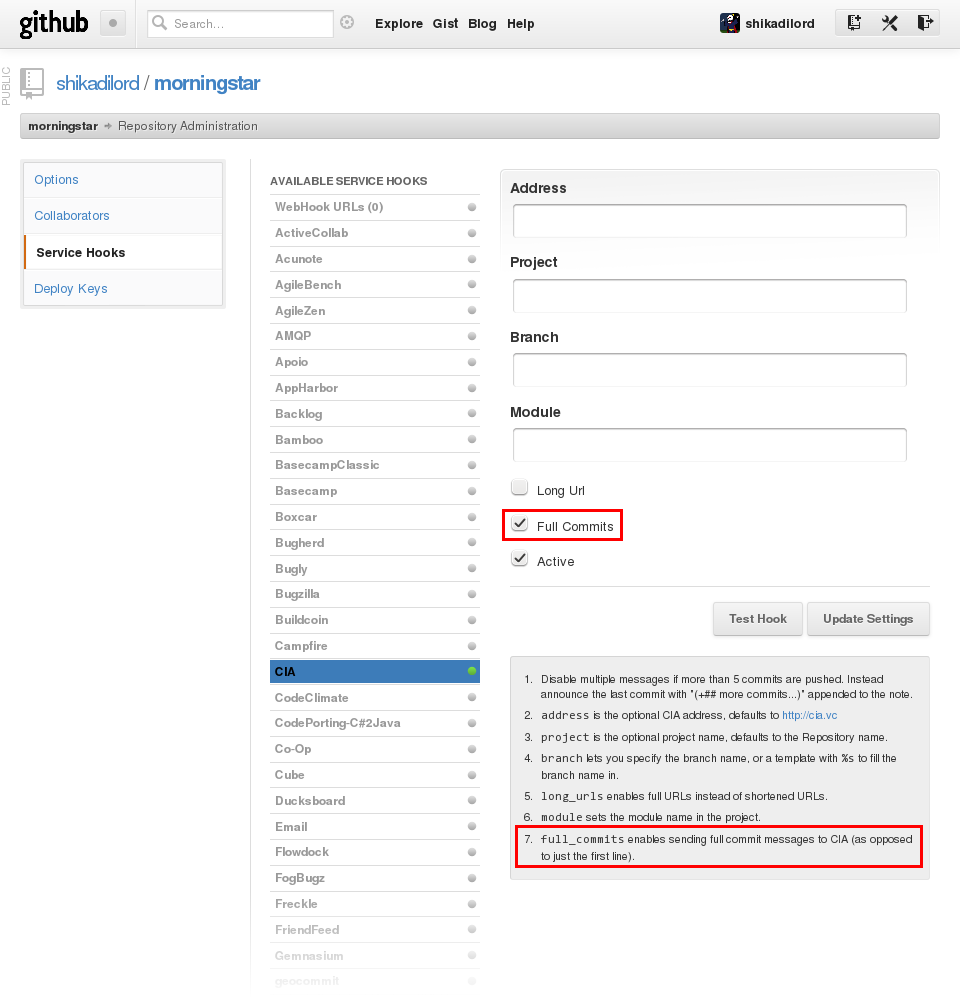
I am definitely not part of that crowd, but I respect people’s right to choose, so I decided to provide them with the choice to get full commit messages sent to CIA.vc. The relevant pull request has just been accepted.
This is what the CIA hook configuration looks like in production now:
I have gone and enabled the option for every repository I currently host at GitHub that’s already using the hook. If you really care about proper Git commit message formatting (or merging commits from people who do) and you are also using CIA, I urge you do the same.
It should be noted that the single commit in that pull request is my very first attempt at writing code in Ruby at all.
Wesnoth-TC 1.5.1 has just been released... or maybe not. It has actually been tagged for more than 24 hours already.
This version is really just a bug-fix release, which is why it’s not 1.6.0. In fact, it only really addresses some build-time issues that have cropped up over the last couple of years.
Windows (Win32) binary:wesnoth-tc-1.5.1-win32.zip (383.6 KiB)
SHA1 checksum: b74f26ea3743917433be4f3ca0c0be1a5647b40b
Instructions
Both distributions come with a README file, and the source code distribution also includes an INSTALL file with detailed instructions for configuring, compiling and installing Wesnoth-TC. The Windows binary distribution doesn't require any installation besides unpacking it into an appropriate directory — which you may optionally add to PATH.
The past, and the future
Long ago, this came into existence. At the time, I needed a quick way to preview my own team-colored unit sprites without going through the hassle of starting/restarting Wesnoth (or its internal cache), loading a saved game, and creating units in debug-mode. That was my initial motivation for writing Wesnoth-TC, and since it was tailored to my specific needs, it was born as a console application. I later decided to publish and extend it, hoping that someone else would provide a good full-featured user interface for it.
Actual artists prefer using graphical user interface applications on Windows and Mac OS X, and with good reason. That’s the software interaction paradigm that suits visual types better for obvious reasons, and that’s why I took it upon myself to write a larger GUI front-end for Wesnoth-TC that could be built and run on the three major platforms from a single code-base.
That front-end quickly became an adaptation of the original back-end code. And thus Wesnoth RCX became an entirely separate project sharing little more than a bit of history with Wesnoth-TC. And most importantly, Wesnoth RCX became the first GUI (Qt 4) application I have ever written.
Over time, my needs and personal preferences have changed. Wesnoth-TC now feels largely inferior to RCX merely because of the lack of a native front-end for it. RCX has also recently gained visual palette and color range editing capabilities, which renders Wesnoth-TC’s definition file system somewhat obsolete. Furthermore, RCX has continued to compile and run correctly over time regardless of the Qt 4 version currently installed, whereas Wesnoth-TC has broken in a few occasions with newer development environments.
Wesnoth-TC truly feels like a relic now, one I don’t really want to continue developing at this time when I feel RCX is more fun to improve and work with. I had plans to eventually integrate a full-fledged implementation of the Wesnoth Image Path Functions mechanism, but that seems over-ambitious right now.
So, yeah, Wesnoth RCX is the future. Stay tuned for version 0.2.0, coming soon with more features and improvements.
I have just finished moving Wesnoth-TC and Wesnoth RCX to Github — in my humble uneducated non-expert opinion, a much nicer place to be than Gitorious, which still lacks native CIA.vc support after all these years. Instead, Github supports CIA.vc and a large amount of alternatives which I’ll probably never use.
The project page on this website has been updated accordingly. If you were tracking the repositories at Gitorious, you will not be able to get further updates unless you update your configuration to point to the new locations:
Updating client repositories is actually far easier than it sounds:
$ git remote set-url origin <new URL>
Afterwards, you should be able to fetch/pull as usual.
This switch actually began some time ago when I was considering resuming Wesnoth RCX’s development (which stagnated ‘some’ time ago too). It took a while, but I finally seem to be back on track, all thanks to my currently unannounced self-imposed campaign development break — a break that should allow me to get back to business soon enough, with the renewed energy and coder momentum I will seriously need in order to pull it off.
Wesnoth RCX 0.2.0 will probably be released before the end of this week, as soon as I make sure everything works as intended, which will be less trivial this time due to the new shiny features it packs. There’s also a couple of Windows-specific oddities that I want to tackle before releasing.
Oh, and in the meantime there will be an update regarding Wesnoth-TC’s future.
I could not bear using Chromium for a week as I originally intended. All right, I admit I always intended to go back to Firefox, but the whole exercise didn’t go as planned for various reasons.
The thing is, I have always used Firefox since version 1.0 or so and it has basically become part of my personal life — it’s impossible for me to stay mad at it for too long after all we have been through together.
Nothing of this renders the points I previously raised here any less valid, but I have coped with those annoyances for a good while already — let’s not get too demanding in the usability department here, otherwise I may as well invest a zillion dollars in Apple products right now.
Besides, Chromium insists on taking up preposterous amounts of CPU time in the background every once in a while, even after getting rid of a certainbug with the Linux kernel and leap seconds. Despite all its inefficiencies, I have never seen Firefox indulge in such erratic (and potentially harmful for laptops) behavior like that while idle. I already did my best to diagnose the issue, but I never had that much interest in using Chromium as my primary web browser in the long term anyway. After all, I am a KDE user, which means I like options — the Chromium design philosophy is more or less the antithesis of that, and it shows.
There’s also these twoseemingly minor annoyances, and this — which makes more sense if you take this (from about 10:58 hours earlier) into consideration.
Not to mention that there’s no Chromium add-on providing a Bookmarks menu that looks nice, probably due to the previously mentioned design limitations. It’s also somehow more natural for me to have the Home button at the right end of the toolbar, but this might just be Firefox inculcating habits.
Going back to Firefox, it does seem like resetting its configuration and clearing all of my old web history before March 2012 improved overall performance. In case someone else wants to try resetting their own configuration:
Backup your profile or the whole .mozilla directory (on Linux/X11, no idea about other platforms);
Go to the about:support page, and choose the Reset Firefox option;
Follow the instructions on the screen to create a new profile preserving your browsing history, bookmarks, cookies, and saved passwords.
When done, you will be left with an additional copy of your old profile that might or might not still work — I didn’t check this. You can start Firefox with the -P switch to see the previous profile, and possibly delete it after you are done making sure all the information you need is present in the new one. You will lose all your installed add-ons, their configuration, and your browser preferences; this is pretty much the whole point of the procedure.
I for one had accumulated heaps and heaps of unused or obsolete configuration entries (both from add-ons and old Firefox versions) carried over since late 2008. That can’t possibly be healthy, especially considering that I have tried many, many add-ons and hidden configuration options over the years, and used pretty much all versions since Firefox 3.0.
It’s probably more important to keep the web history under control, though. Older versions of Firefox—if I recall correctly—had a user-visible option in Preferences to limit history to a given amount of time, but that doesn’t seem to be the case as of Firefox 13 and it’s all or nothing. Of course, it’s also possible that the current defaults do limit history and there simply isn’t a way to change that limit anymore; so if I ever changed it with a previous version, it would have become inaccessible to me later short of using about:config.
These two images are not the same, at least if you are using the default Firefox configuration on Linux/X11 with gfx.color_management.mode set to 2 (only tagged) instead of 0 (all disabled). It turns out I disabled that setting entirely at some point—for some reason—and later forgot about it.
To be more specific, the image to the right is the intended rendering. This is what the side-by-side comparison above should look like with the defaults.
It also seems I have been leaving behind a trail of PNG files in the web that contain bogus ICC information that causes Firefox—again, with the default configuration—to render them differently than I actually intended when exporting them in the GIMP. In the case of my avatar, it’s not a big deal since it’s just Xykon from the Order of the Stick serving as my terrifying spokesman spokeslich. However, if my memory serves me right I have seen this being an actual issue with my whole website layout in my default-configured virtual machines — and I always dismissed that color disparity as being caused by VirtualBox instead of Firefox.
Thankfully, the website CSS currently makes more use of browser gradients to prevent the faulty (?) graphics being used in practice. The spritesheet that contains the post category icon (used in the front page) is evidently affected, though.
But to what degree is it Firefox’s fault? Unfortunately, I understand jack shit about color profiles and I don’t seem to have a tool handy to tell me what the technical differences between both images are. I suspect I did something wrong in the GIMP at some point, or perhaps the problem was created by my application of a certain PNG optimization script. Does the wrongly rendered version of my avatar actually have color profile information in it?
What I do understand is that color profile information in PNG files has bitten my ass several times over the years, and not just with Firefox, but also with Wesnoth (via SDL_image).
If anyone there thinks they have a definitive answer to this conundrum, please share.
EDIT: Yes, I reuploaded my avatar to the Wesnoth.org forums and my Twitter profile during the last couple of days in order to fix this issue. It was just matter of opening importing the current versions in the GIMP and then saving exporting the unaltered contents to new files. I will probably try the optimization procedure on the fixed versions later.
EDIT 2: Also, yes, I am aware that the two sample images look identical in non-Gecko browsers.


{kind=link}